
Many scientific codes in research are developed in an organic way: you need a feature, so you code a feature. Perhaps it is a command line program that now needs to process the input data differently and output result data to a file in a different format. So for convenience, you code the extension in a single location in your program. It works, you understand it (and others can understand it!), and it is well tested. It's good, right? Maybe. But let's take a more thorough look...
Bookmark this page
Bookmarked
Developing scientific applications using a Model-View-Controller approach
By Steve Crouch.
Many scientific codes in research are developed in an organic way: you need a feature, so you code a feature. Perhaps it is a command line program that now needs to process the input data differently and output result data to a file in a different format. So for convenience, you code the extension in a single location in your program. It works, you understand it (and others can understand it!), and it is well tested. It's good, right? Maybe. But let's take a more thorough look...
Why write this guide?
This was suggested by an attendee at our Collaborations Workshop 2012.
Let's take a look into the future
But now consider if you were to extend your code many times in a similar manner, perhaps fulfilling a new research objective each time. And then, a fundamental requirement pops up: the program needs to provide its functionality via the web to scale out its accessibility to users, or perhaps via a graphical user interface to cater for less technically proficient users who want to adopt it. Alternatively, a developer external to your project wants to extend your code in one of these ways. But unfortunately, all these changes have resulted in code that isn't easy to modify, with all the processing, input and output handling mixed together in an ad-hoc way in your program. What should have been done differently to make this more straightforward from the outset? Or how could you refactor existing code to avoid this in the future?
Separation of concerns
If we could separate out these various aspects (i.e. handling user input, displaying output, processing) into logical chunks or modules, it would be far easier to extend or modify each aspect in the future. And since it is more logically organised, it would be easier to test, maintain, and reuse its parts elsewhere.
The Model-View-Controller architecture
This is where the Model-View-Controller (MVC) architecture (or design pattern) comes in:
- The model represents application data and rules for manipulating that data. Perhaps a single data object, or series of objects
- The view is some form of visualisation of the state of the model
- The controller provides the ability to change the state of the model or manipulate the view
So how is this done in practice? Consider this very web page! In a typical web-based application you have:
- HTML - the model: handles the knowledge of the page - its content
- CSS - the view: the visual style that presents the HTML, or model
- Browser - the controller: allows modification of the model and view e.g. through forms (e.g. PHP) or JavaScript (e.g. JavaScriptMVC)
It is also a common pattern in desktop applications. A good example is in Microsoft Windows, where you have various accessibility features to access the system like a mouse/scratchpad, keyboard/speech recognition (controllers), and localisation and desktop themes (different views).
So how does this apply to scientific applications? It's actually quite simple:
- Model: this comprises those parts of the application that deal with some type of scientific processing or manipulation of the data, (e.g. numerical algorithm, simulation, DNA)
- View: a visualisation, or format, of the output (e.g. graphical plot, diagram, chart, data table, file)
- Controller: the part that ties the scientific processing and output parts together, mediating input and passing it to the model or view (e.g. command line options, mouse clicks, input files)
So, in your software, you would have each of these aspects in separate modules, with well-defined interfaces for tying these parts together, i.e. in the Controller. Bear in mind that MVC isn't always suitable, especially for small programs where it would be more difficult to realise the advantages and clarity due to the architectural overhead. So ensure it is a sensible approach for your software first.
A simple example is given in the diagram below:
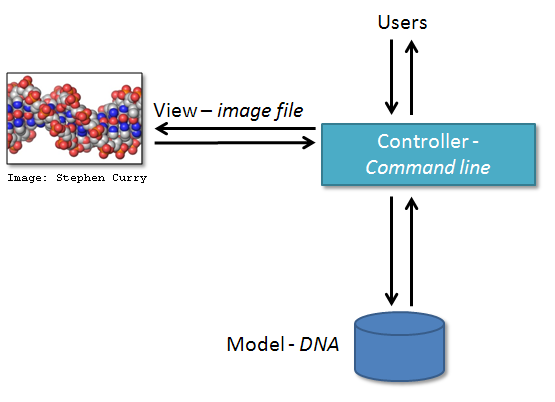
Here, we have a simple DNA visualisation program. There is a controller which accepts command line parameters for the DNA visualisation from users, and the controller retrieves data from the DNA model, and uses a single type of view to generate a visualisation - in this case, the view creates a visualisation within a single image file.
The advantages
If MVC is the right approach, there are a number of advantages to using it. For your software, because you've separated out the various functions of the code it can make it easier to:
- Extend: with our above example, adding new visualisations or new input interfaces is just a case of writing a new view or controller, without having to consider the inner workings of the model or the other aspects. In our previous simple DNA program, we could extend it by adding another controller (a graphical interface which accepts user mouse clicks), and a different view (in this case, it renders the visualisation to a displayed window):
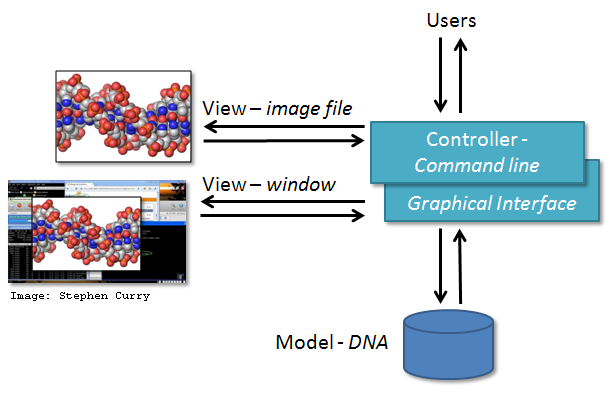
- Validation: this also gives you another route to validating your scientific code, e.g. you could potentially write a wrapper for someone else's scientific model that conforms to your MVC interface, and see how it compares.
- Test: now you have separate models, views and controllers, it's much easier to test each aspect individually and debug the code. And importantly, it can be much easier to automate testing e.g. to just test the scientific core (model) by writing tests to just use the model interface.
- Reuse: with well-defined interfaces it becomes much easier to take one aspect and use it elsewhere, e.g. you could reuse the model (in its own standalone library) in someone else's code. A good example of this is the COPASI biochemical network simulator. Due to its modularity, its simulation model has been used separately in the Systems Biology Software Infrastructure (SBSI) application suite.
In short, it can help the software to be more maintainable and reusable. It also provides a recognisable structure to other developers, who can more easily come to grips with your software. So really, MVC is simply a good example of modularising your code, which you should do anyway! Even if it's not appropriate for your own software, it is always a good idea to think along these lines so you end up with a good overall structure.
So what should be a rule of thumb for developing MVC applications? A really good one is 'We need SMART models, THIN controllers and DUMB views'! So, keep your controller code small and your view code simple (although typically these can be quite large) whilst acknowledging your domain model code could well be complex, which is ideally where the only complexity should be.
Implementations of MVC
There are many implementations of MVC, especially for web applications such as RubyOnRails, Django, CakePHP, AngularJS, Spring and ASP.NET.
Of course MVC is not language, framework or domain specific. For your own custom codes, say in our example scientific application, you would design the system to take MVC into account. A good overview of how you might do this in C++ can be found here, which could easily be applied to other languages.
A Derivative of MVC - Model-View-Presenter (MVP)
In the Model-View-Presenter derivative of MVC, the presenter assumes responsibility for all presentation logic. In MVP, the separation of concerns are improved - the view is responsible for routing user commands to the presenter to act upon, and this further decoupling makes automated unit testing of the view and the model easier. For this reason, it is a common pattern for implementing web forms.
Further reading
- An overview of MVC from Wikipedia.
- An overview of MVP from Wikipedia.
- Model View Controller from Cunningham & Cunningham, Inc.