
Overleaf as a collaborative tool for scientific writing
Time: Monday 26 March 2016, 17:15 - 17:50
Speaker: Vincent Knight, Cardiff University.
Where: M/0.40.
This workshop will introduce participants to LaTeX (a typesetting framework for scientific writing) with Overleaf.
As well as going over starting with LaTeX for those who have never used it before (and perhaps heard a lot about it), it will also cover some of the great tools that overleaf has to offer for collaborative writing which will include:
- A rich text editor for collaborating with non LaTeX'icians,
- A Git bridge that allows you to work locally and/or in the cloud.
Finally, time permitting, some best practice tips on using LaTeX with software outputs will also be discussed.
Making research software easily citable with the Citation File Format
Speaker: Stephan Druskat, Humboldt-Universität zu Berlin.
Where: M/0.34.
The Citation File Format (CFF) is a human-readable and -writable, and machine-readable file format for the provision of citation metadata for software, as well as more general software metadata. It is a source format for CodeMeta JSON files, which are emerging as the standard for describing software metadata. CFF attempts to provide an easy access to the provision of software metadata especially for RSEs and researchers who create software, who may be less engaged in the software citation community or new to the concept of software citation and its principles, but want to start providing software metadata in order to gain well-earned attribution and credit for their work. CFF aims at implementing the software citation principles as put forward by the Software Citation Working Group at Force11, for the most common citation cases, such as citing a used software in a paper, re-using a software in a new software, or managing references for software in a reference manager. CFF has been designed as a bridge between the current state of the practice in research software citation - the provision of plain-text or language-dependent CITATION files, referencing papers, or no provision of citation metadata at all - and a best practice in software citation, e.g., via the implementation of transitive credit for software. In this session, I plan to present the basic concepts and usage of CFF (and its tooling, currently in its planning stage), and hope to engage in a discussion about the format, its potential, and the future directions it may take.
Code is Science - open source scientific code manifesto
Time: Tuesday 27 March 2016, 14:40 - 15:15.
Speaker: Yo Yehudi, University of Cambridge.
Where: M/0.40.
Given the large amount of data available, science these days often relies upon software to analyse and create scientific results. Despite the fact that software is a critical step in science, much scientific software remains closed source. Scientific authors routinely write papers about their code, gaining ‘academic credit’ for their work, without the code that produced the science having been peer reviewed for quality and correctness. This is a shocking state of affairs, given that errors in the code will produce errors in the science. Imagine a mathematics paper that didn’t include the mathematical proofs it was talking about - this seems ridiculous! So why does it happen with computer code? Code Is Science is an initiative that aims to work with scientists, research software engineers, journals, and funders, promoting open source code and encouraging journals and funders to build requirements for open source into their frameworks. One goal is to create an Open Source Code manifesto outlining the importance of open source code in science, allowing funders, journals, and even research institutions, as well as ground-level scientists and engineers, to commit to comply with our vision.
Python testing with pytest
Speaker: Matt Williams, University of Bristol.
Where: M/0.34.
In recent years, pytest has become known as the foremost testing package for Python. This session will cover some of the advanced features of the tool to allow more reliable, extensive testing. It will cover the built-in pytest fixtures such as xfail, skip and skipif to control which tests are run and where. Pytest's custom fixtures are also a powerful tool to setup and teardown your test environment without too much boilerplate so they will be introduced and explained. Mocking and mokeypatching have become a popular way to isolate parts of your system while writing integration tests and pytest provides a built-in solution to make life easier; both 'when' and 'how' will be covered. Finally, I will introduce Hypothesis as a tool for automatically generating test cases and finding minimal reproducible cases.
The Software Engineering Initiative of the German Aerospace Center
Speaker: Carina Haupt, German Aerospace Center and Tobias Schlauch, German Aerospace Center.
Where: M/0.33.
The German Aerospace Center (DLR) conducts research and development in the domains aeronautics, space, energy, transport and security. Software development plays an increasing role in DLR`s research activities. Around 2000 to 3000 persons develop software – in part or full time. Typical development team sizes range from one up to 20 persons. To support such small development teams from different research domains and to establish basic quality of produced software are important challenges. For that reason, DLR started its software engineering initiative to improve sustainability and reproducibility of software products. The goal of the software engineering initiative is to encourage scientist to form a self-reliant software engineering community. We try to support this by providing information resources and opportunities for collaboration and exchange. As part of this we established common guidelines with focus on small development teams and perform supporting activities such as providing development tools and supporting knowledge exchange.
In this workshop we present the different activities of the software engineering initiative and tell about our journey to establish them, which experiences we collected, and what we learned. We want to discuss our approach, how it can be reused by others, and are looking for feedback as well as experiences of others.
A Registry for Research Software Repositories
Time: Tuesday 27 March 2016, 15:15 - 15:50
Speaker: Alexander Struck, Humboldt-Universitaet zu Berlin.
Where: M/0.40.
This session investigates the use cases for a registry that holds information about research software repositories. Software is slowly recognized as an integral part of current research. But research software still faces several obstacles. To name a few:
- Funding agencies consider software as research data. That causes problems in some areas. One is the application of e.g. FAIR principles [1]
- Recognition for writing software (to solve scientific problems) is almost non-existant. Neither in funding applications, nor in job descriptions. Part of the problem is the difficulty and/or heterogenity to cite (pieces of) software as a research result.
- (Almost) Every research software project starts from scratch.
- Publication of and Information Retrieval for research software is scattered. Software is talked about in articles. Some is hosted on Github, other in closed repos, an unknown number on drives.
- Aging and Death. If software is not updated it may age so fast that it becomes unusable in months or years. Regularly, for research software the bus factor is rarely greater than 1.
Focusing on Information Retrieval:
A much needed attempt to list repositories is made by re3data.org. Research data repos AND software repos are mixed there for some reasons. One being the entanglement of some data sets with software. In e-mail conversation the creators of re3data.org describe their current implementation as "pragmatic".
Unfortunately "usage data is not available". A request for criteria to reject certain repositories was answered with "unavailable". According to a short survey on an international list for Research Software Engineers, only one person knew about it and no-one from this community uses it.
Some criteria to include repos are questionable:
dbpedia is indexed with the terms (content types):
- Databases
- Scientific and statistical data formats
- Software applications
- Source code
- Standard office documents
- Structured text
- other
We argue, that such an indexing would create too many false positives for the information seeker. They currently have the following numbers of repos classified as hosting Source Code or Applications:
https://www.re3data.org/search?query=&contentTypes[]=Source%20code(112)
https://www.re3data.org/search?query=&contentTypes[]=Software%20applications (370)
Here we have to ask: Would it make sense to separate software repositories and offer them in their own registry, since Pampel et al. [2] seem to aim at data but not software?
In this session ideas and needs for software information retrieval are introduced and discussed.
Who is the target audience?
What content should (not) be included?
Do you need to write state-of-the-art reports when applying for funds for another research (software) project and would such a registry help?
What kind of fields/metadata would you expect when searching for software repositories?
Do you know enough software repositories to find and/or publish software? Does any of them provide an executable environment?
Would you like to see dependencies and metrics listed in such a registry?
[1] https://danielskatzblog.wordpress.com/2017/06/22/fair-is-not-fair-enough/
[2] http://journals.plos.org/plosone/article?id=10.1371/journal.pone.0078080
Building Effective, Sustainable, Research Software Communities
Speaker: Jeremy Cohen, Imperial College London.
Where: M/0.33.
As the profile of Research Software Engineering (RSE) grows, RSE groups and networks continue to be set up at institutions both within the UK and internationally. This activity is giving researchers, academics, and RSEs themselves, a better understanding of the benefits of RSE groups, networks and communities, but also the challenges that are raised in trying to ensure effective and sustainable support for RSEs and researchers undertaking significant software development work. This work is often carried out within siloed domain-specific research environments that have their own approaches and methods for undertaking software development. This session will investigate what helps to make RSE communities work, what participants feel they benefit from and what they feel is less useful. The session will not offer you a recipe for building an effective RSE community. Indeed, RSE communities can differ significantly with different aims, focuses and member profiles. Nonetheless, they do share elements in common and challenges encountered in one community are often present in others. Following a short introductory presentation, the focus will be on interactive discussion providing an opportunity to share thoughts and ideas around improving the provision of RSE community support and learning from the experiences of other attendees. How will you benefit from attending this session? The session will: provide an opportunity to learn from other RSEs and group leaders' experiences on what activities do and do not work in RSE communities; enable you to put forward your thoughts on aspects that you feel are currently missing from RSE community activities; help you to understand what you might be able to do to support, sustain and grow a local community of RSEs.
The rooms that will host the mini-workshops and demos sessions don't have any screen capture system. We encourage mini-workshops and demos sessions speakers to capture their screen and record their audio, such that we can publish the video on our YouTube channel and associate it with CW18.
Audio Record
We will provide USB Jabra microphones for those that would like to capture their activity.
Video Capture
We are looking for a screencast. You can use any screencast tool available for your operating system. Wikipedia has a decent list. In case you want a suggestion from us, we recommend Open Broadcaster Software (OBS) Studio because it works on Windows, macOS and GNU/Linux and is free and open source.
Open Broadcaster Software Studio
Instructions to download and install are available at https://obsproject.com/download.
The first time that you launch OBS Studio you need to agree with the GNU General Public License Version 2 and will opt-in to run the auto-configuration wizard. Before record your video, you can configure where the video will be store.
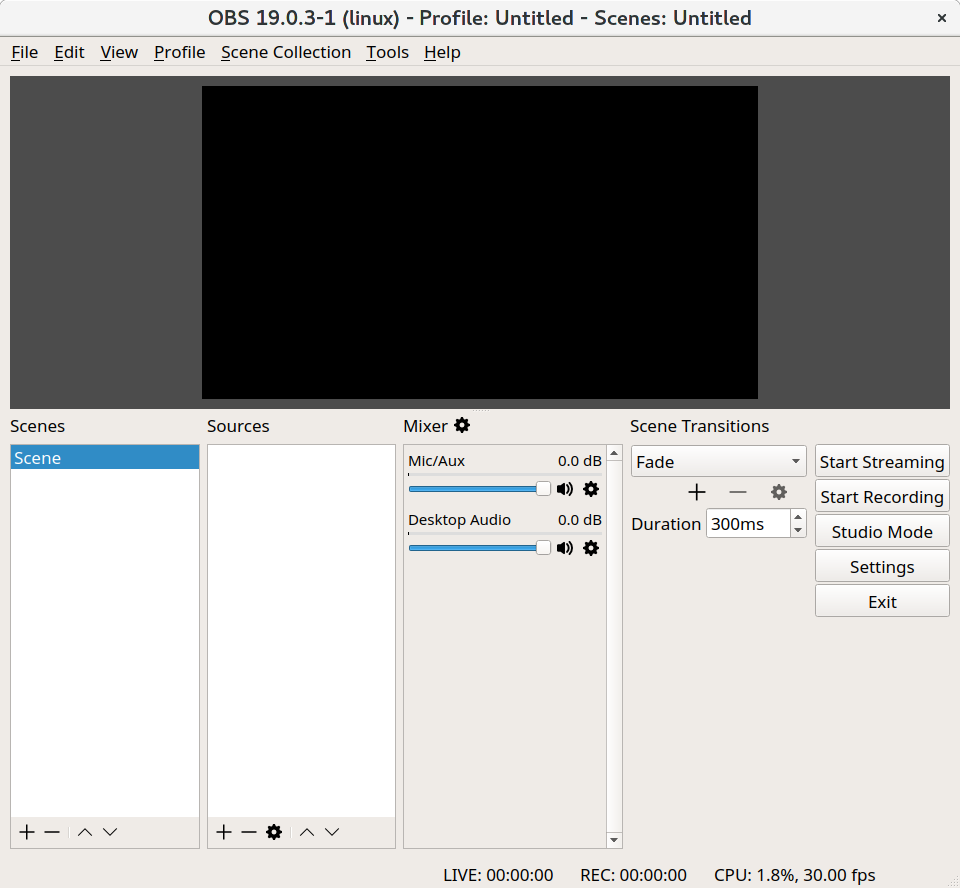
On the menu bar, select "Files" and "Settings".
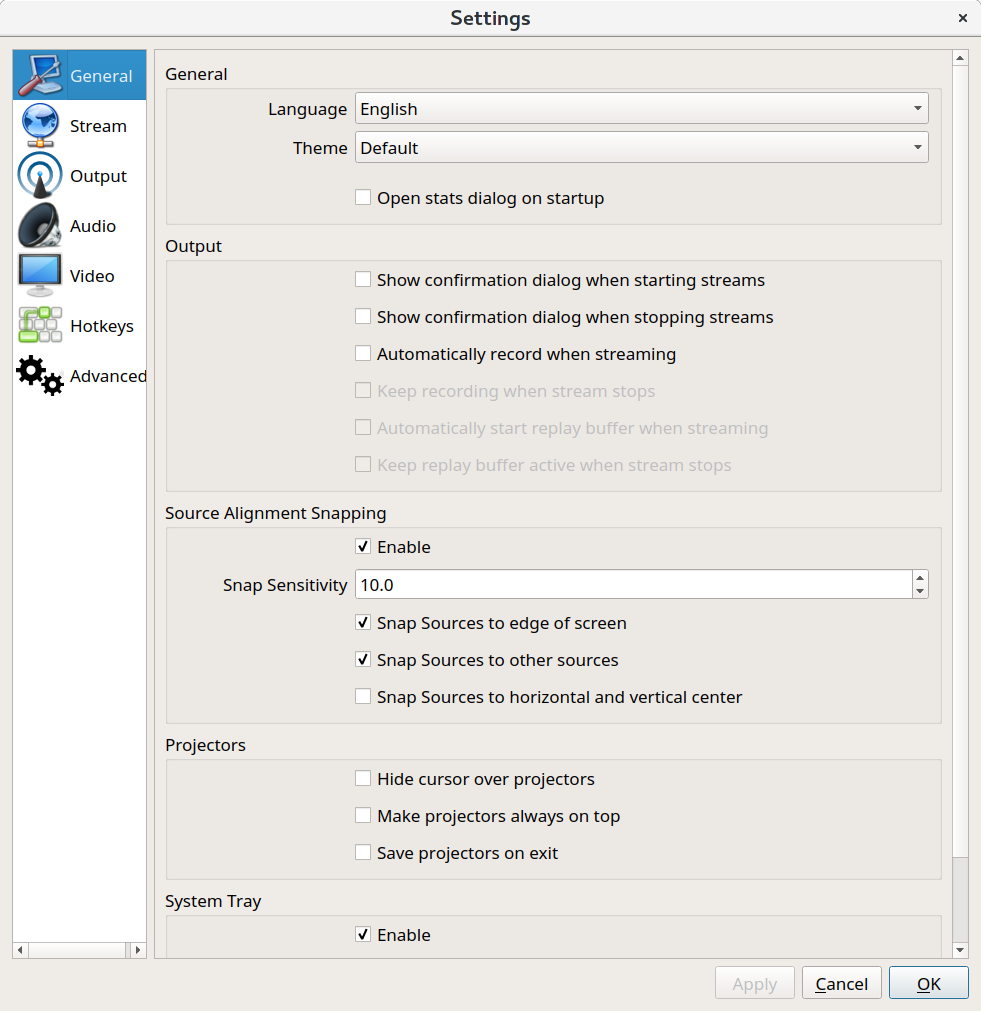
On the left menu, select "Output".
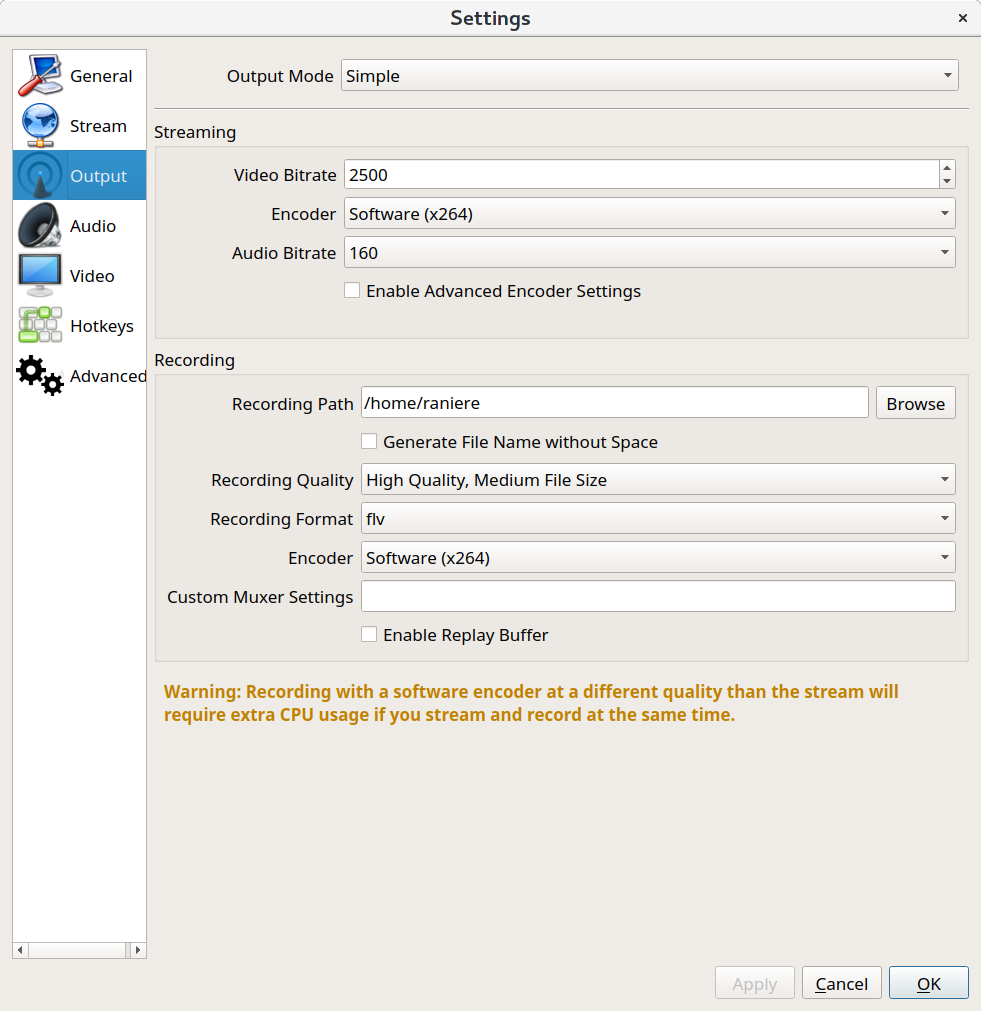
At the "Recording" options, configure the "Recording Path" for where OBS Studio should save your video and select "mp4" as the "Recording Format". At the bottom right, click on "OK".
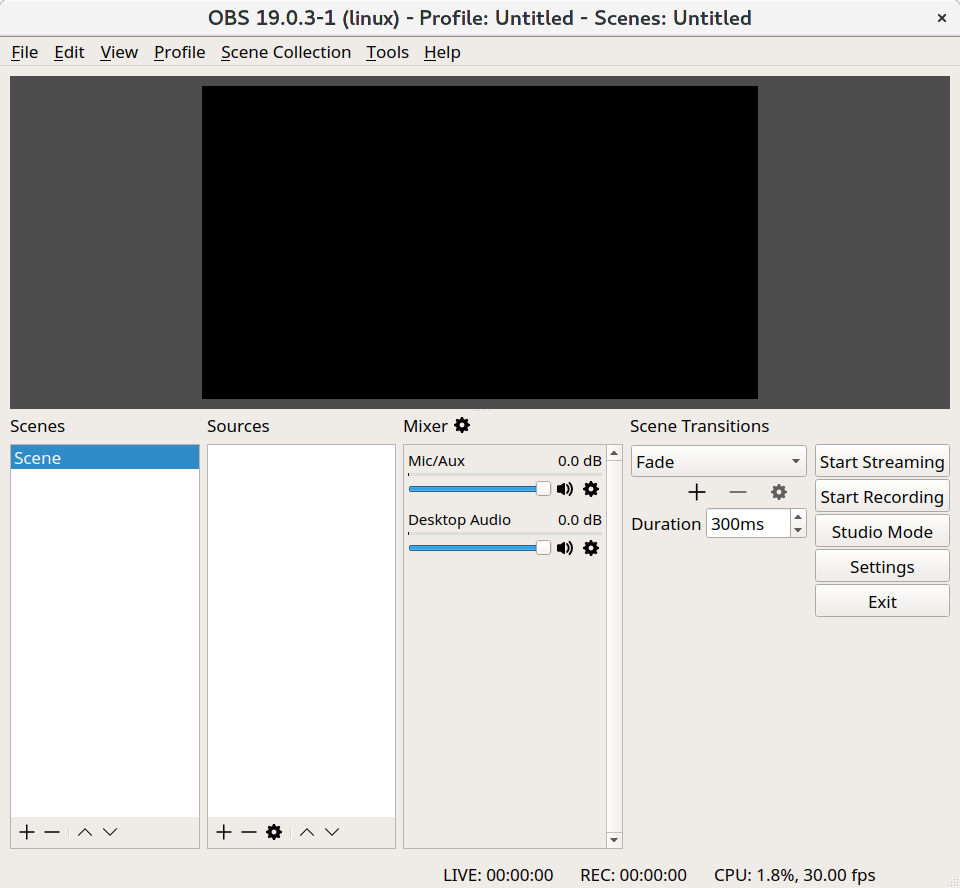
Back to OBS Studio, you need to add the "Sources" (second column from left to right). Add "Window Capture" and "Audio Input Capture".
When adding the "Window Capture" you need to select which window you want to record. If you want, you can disable the "Capture Cursor". In some cases, the red and blue are swapped—you will noticed on the preview. If this happen need, you should enable "Swap red and blue".
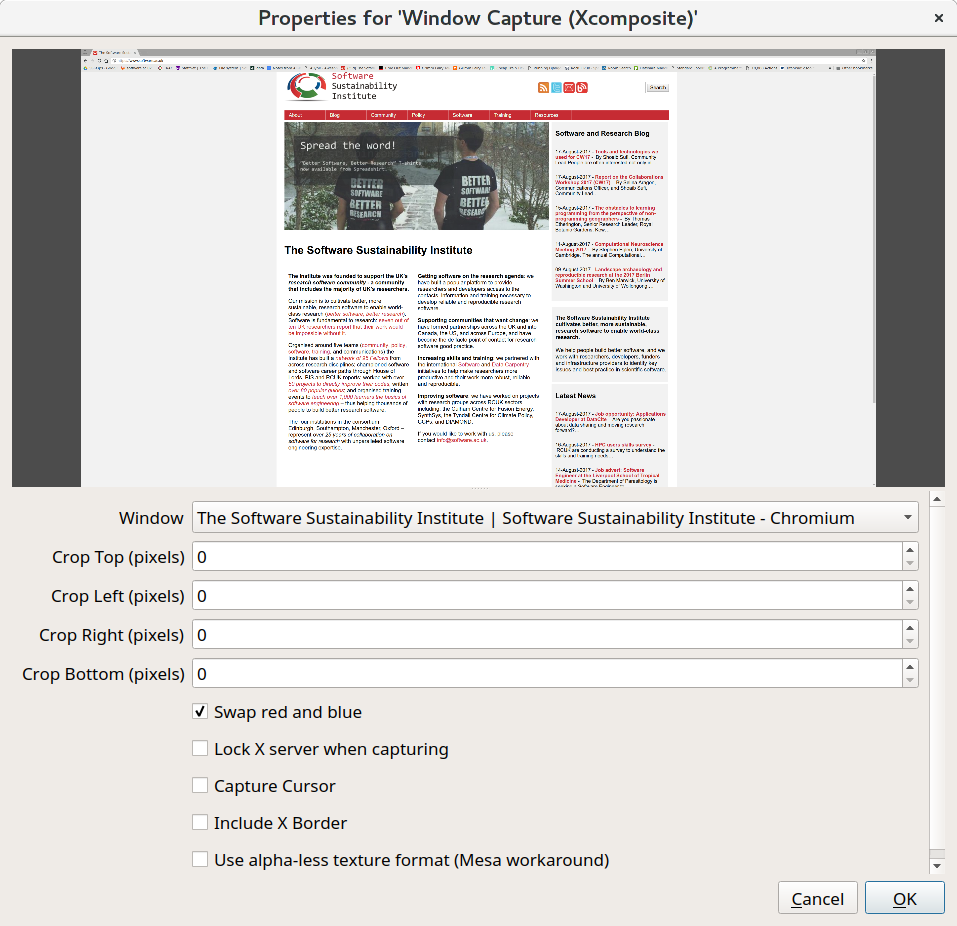
-
When adding "Audio Input Capture" you need to select the device you want to capture. We recommend to use a external microphone for better audio capture.
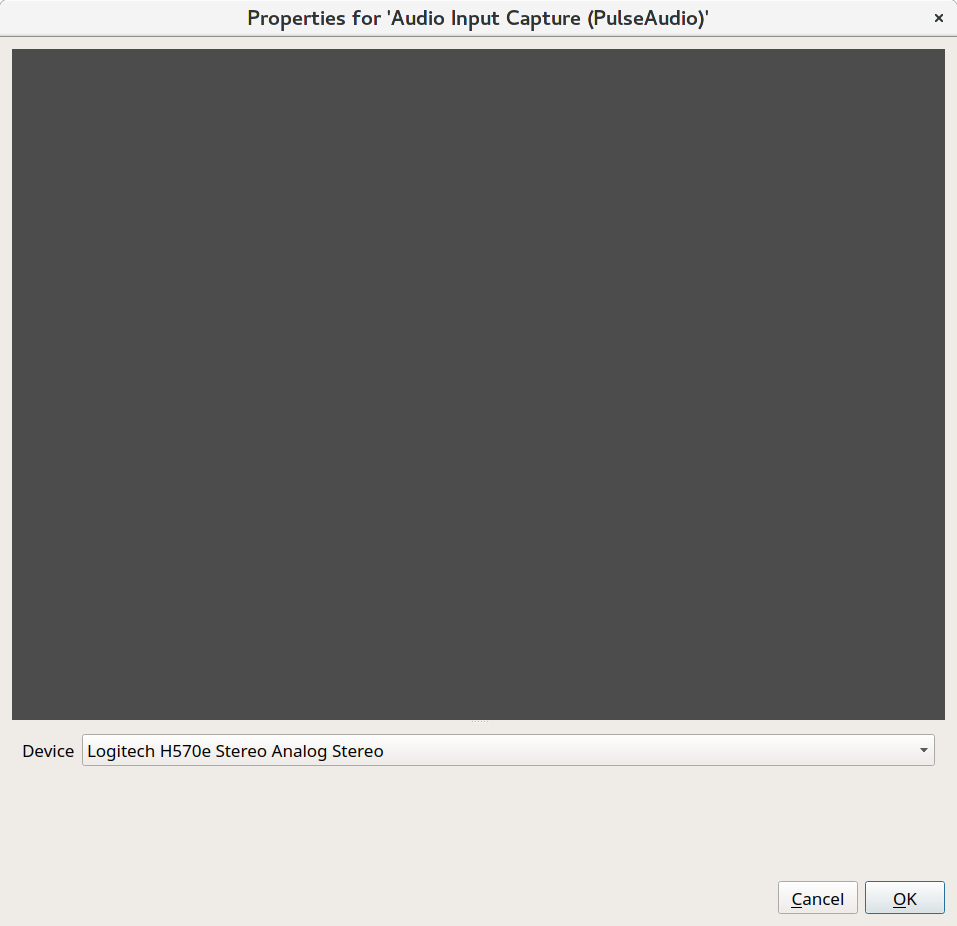
If you need to change the "Sources" properties you can double click on the source to change it.
To start recording your video, click on the "Start Recording" button.
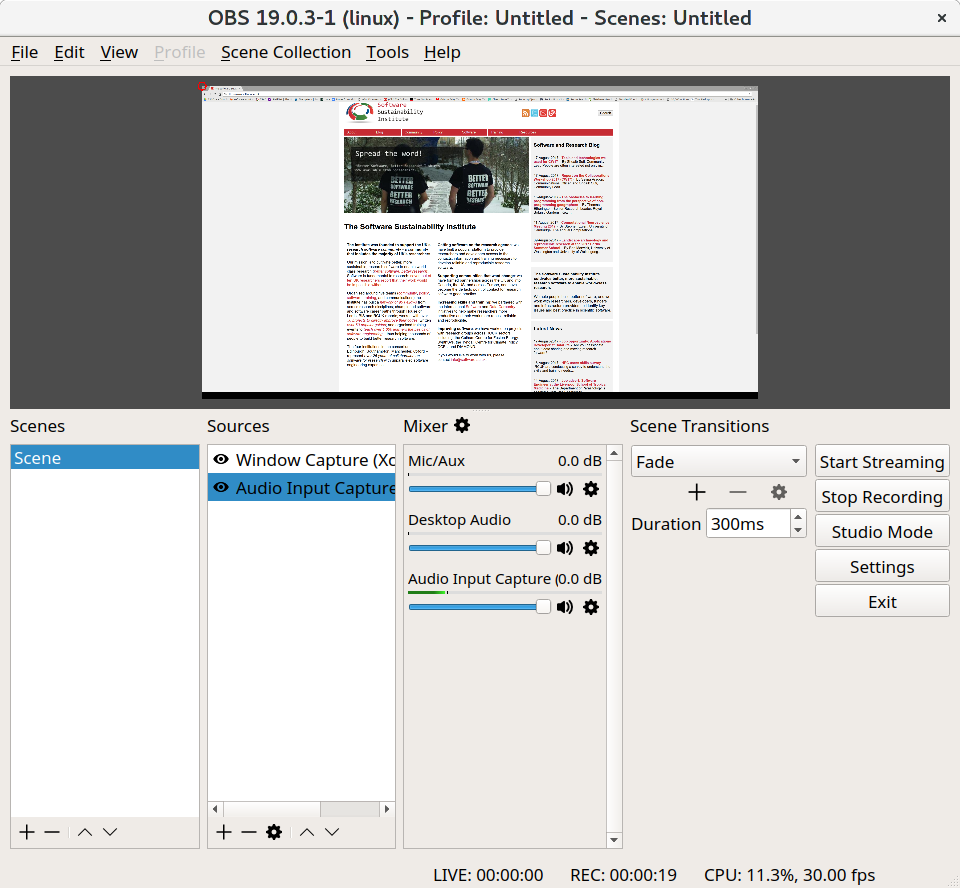
When the record starts, you will see the clock on the bottom change and there will be a button to "Stop Recording".
Video Upload
- Open https://www.dropbox.com/request/nEmhwkkNd8ozPXmkqe8i.
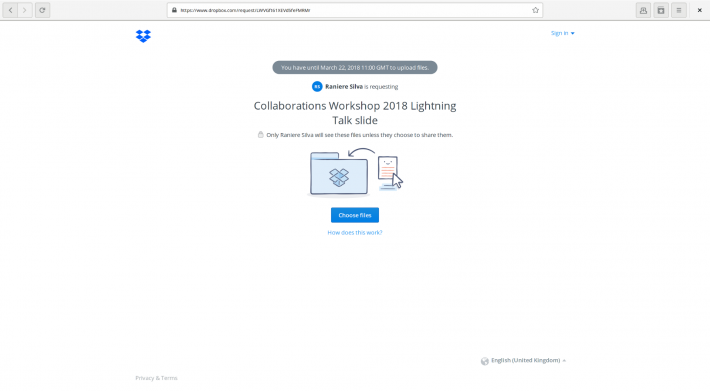
- Click on the "Choose files" to select your video slide.
- Fill the fields "First name", "Surname" and "Email address".
- Click on "Upload".