
First steps to a guide for computational access to digital repositories
 Workshop participants were sent cookies /brownies for the break
Workshop participants were sent cookies /brownies for the breakBy SSI Fellow Leontien Talboom.
Within the digital preservation community, the term computational access is popping up more and more frequently. It is often linked to other terms such as artificial intelligence, data mining and deep neural networks. However, there is often little understanding of what these terms actually mean and how they relate to each other.
With the help of the Digital Preservation Coalition (DPC), and namely Jenny Mitcham and William Kilbride, I am setting up a guide to provide digital preservation practitioners with the first steps to approaching computational access. This guide will also provide an opportunity to explore the term of computational access within the digital preservation context in more detail. Currently it is related to providing users access to collections to be able to compute over this material. The guide will build on earlier work within the field, for example the ‘Collections as Data’ project, but also the work done around scoping and enabling different technology within the field.
However, there is a focus within the community, and in research as a whole, on exploring the new and novel techniques that are available. Also, the emphasis is on what can be done from a researcher’s point of view, forgetting about the practicalities of making this material available from a digital preservation practitioner’s point of view. This guide will therefore look at contextualizing computational access within the digital preservation framework and providing first steps, practical tips and resources to practitioners wanting to implement this approach for their users.
Expert Workshop
To move forward with the guide it was decided that an expert workshop would be a great place to get started. The invited experts are people working within the digital preservation community, or people closely linked to this community. Experts were invited from larger institutional repositories, smaller regional repositories, libraries and government organizations. It was important here to ensure that the invited speakers were familiar with different types of material and were from different backgrounds, to ensure that as many perspectives as possible were represented during the workshop.
The workshop itself focused on a number of topics that were explored in different ways. There was a discussion around terms related to computational access, and what terms should be outlined in the guide, such as artificial intelligence and machine learning.
There was also a discussion on first steps and the benefits or drawbacks of applying computational access for different institutions. This was explored with the help of a Jamboard. We also discussed the outline of the guide and what should or should not be included within it. We asked our experts to list useful resources within a spreadsheet, which will come in handy later on when writing the guide. This workshop gave us some great insight into different discussion points and has ensured a good starting point for the guide.
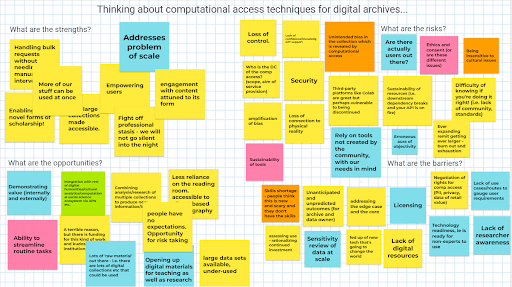 A Jamboard created during the workshop, focused on the strengths, opportunities, barriers and risks of computational access techniques.
A Jamboard created during the workshop, focused on the strengths, opportunities, barriers and risks of computational access techniques.Next steps
This workshop is only the first step in creating this guide. The next step will be to write the guide, which is currently underway. It will then be circulated with the experts again, who will be able to contribute their own sections to the guide - it is important here to ensure this work is done collaboratively and as many perspectives as possible are being covered. The guide is aimed to be finished at the end of June and will be made available on the DPC website, who have experience in publishing online resources for the digital preservation community (see for example the EDRMS Preservation Toolkit or Digital Preservation Policy Toolkit).
To promote the guide, a number of public events will be happening over the summer, including a launch event at the start of July. This will include an overview of the guide, and we will be inviting a number of speakers to present a case study outlining their work in computational access. We are also planning to promote the guide at iPres, the biggest digital preservation conference, which will be held in Glasgow in September