
Testing in Research Software: Review of ICCS 2021 and SeptembRSE
By SSI Fellow Matthew Bluteau.
On 16-18 June 2021, I attended the International Conference on Computational Science (ICCS) 2021 and subsequently wrote a blog post summarising the first part of the Software Engineering for Computational Science (SE4Science) track. True to my word, I am back to complete the review of that track. The remaining part consisted of a speed blogging session, and my group focussed on software testing. Before ploughing ahead, it is worth mentioning that a lot of time has passed since this session, and notably the annual RSE conference returned in online form as SeptembRSE. Unsurprisingly, there was also an event at SeptembRSE that touched on software testing, so it seems natural to briefly review that event as well.
Speed Blogging at SE4S Track of ICCS
The notes from the speed blogging session are openly available in a Google Doc. Like many such sessions, we took quite a winding road across a variety of subjects, but I think predominantly we grappled with the question of how to make software testing, and particularly automated testing, accessible and relatable to researchers who already spend time on scientific verification and validation of their codes. Evidently, this is a large subject to unpack, but ultimately we decided to narrow down to a single factor that could help accessibility: expectations.
There are myriad different forms of software testing out there, and if a researcher or RSE doesn’t know which type of testing is appropriate for the software they are writing, then they will become overwhelmed with the options available and simply not do it. As a result, we came up with the idea of having a chart/table that provides a guide for what types of testing are expected at different maturity levels of research software. Breaking down maturity levels is somewhat arbitrary but an important task when communicating expectations. We ended up using something quite close to the DLR Application Classes:
- Level 0: Personal use
- Level 1: Research within a team
- Level 2: Supported library for research community
- Level 3: Product formally released to broad audience
- Level 4: Critical application for operation
After agreeing on these levels, we then started to assign different testing types to the levels and to the transitions between levels. What eventually resulted after some tidying up by Neil Chue Hong is this table.
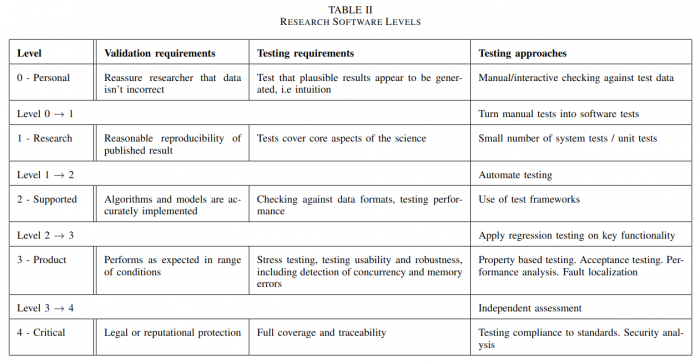 Table II from Chue Hong, Neil Philippe, Bluteau, Matthew, Lamprecht, Anna-Lena, & Peng, Zedong. (2021). A Framework for Understanding Research Software Sustainability. Collegeville Workshop 2021, Online. Zenodo. https://doi.org/10.5281/zenodo.4988277
Table II from Chue Hong, Neil Philippe, Bluteau, Matthew, Lamprecht, Anna-Lena, & Peng, Zedong. (2021). A Framework for Understanding Research Software Sustainability. Collegeville Workshop 2021, Online. Zenodo. https://doi.org/10.5281/zenodo.4988277 For me, it is the leftmost column “Testing Approaches” that delivers the practical value. It tells a miniature story about how the testing should evolve as your software project matures. It starts in a familiar place for personal software projects at level 0: do some manual and interactive checking of the results from your code against some sort of oracle or reference. This is what all researchers already do; however, as soon as the use of the software expands beyond the individual, there needs to be work towards formalising tests in the software. For example, you want to share an analysis routine you just wrote with someone in your research group. Before you do that, this chart suggests that you write something that tests your routine. It doesn’t need to be a test using a formal testing framework, but there should be something codified to test that the routine works correctly. It could be a script that provides some well studied input and output to your routine and against which the user can verify that the numbers match what they get.
This might sound like a lofty ideal that no researcher is ever going to have time for, but think about it more. When you share your code, you are going to need to provide some instructions about use and expected output. It is not that far of a leap to provide a script that does this, at which point you basically have a software test. Moreover, there is whole lot that can go wrong between you sharing a piece of software and someone else using it on their own machine. Having some form of test gives you the piece of mind that the software goblins aren’t plotting to ruin your day sometime in the future.
Naturally, if your software progresses further and continues to mature, then the software tests should concurrently increase in formality. There will obviously be differences of opinion about where the thresholds for different types of testing lie, but generally I quite like where we arrived at as a group in our discussion. I would like to see testing frameworks being used in software that was written for a publication, but in this era of publish or perish, I understand that this is an unreasonable expectation. However, once the software escapes the confines of a single research group, the expectation for automated testing then becomes reasonable.
Discussion on Testing at SeptembRSE
Everything above is immediately relatable to the discussion session at SeptembRSE titled “Is testing overkill for most research software? How can we make it easier to test scripts?”. You can watch the full session on YouTube:
To tersely summarise the response to the first question in the title, participants quite uniformly said, “No. Testing is not overkill”. Of course, the response to that question depends on what type of testing one is talking about. A full suite of automated unit, integration, and system tests in a testing framework that is run in CI is probably overkill for a lot of research software, especially the projects at level 0 and 1 above. Indeed, the participants in the discussion did acknowledge there is a varying degree of software testing dependent on the maturity of the project, which largely agrees with the table we created above.
On the question of how to make it easier to test research software, there was one answer that stood out for me, and I will paraphrase it as “write tests early and often”. The earlier you start writing tests, the easier it will be compared to further down the line. This is because testing has a direct positive influence upon the design of your software. Unit tests in particular force you to write small reusable pieces of code, and if you find it difficult to test something you have written, that is probably because it exhibits some pathology of poor design.
Whilst I do really agree with this answer, I think it also needs to be tempered with the reality of how research is conducted, and in that respect I once again point to the table created above for what should ultimately guide researchers and RSEs when writing tests for their research software.