
Review of the SE4Science Workshop at ICCS 2021
By SSI Fellow Matthew Bluteau.
On 16-18 June 2021, I attended the International Conference on Computational Science (ICCS) 2021, and I want to relay some of the important pieces of information that I picked up. By its nature, it is a conference that encompasses a broad spectrum of scientific domains, from computational health and bioinformatics to quantum computing to flow and transport physics. Whilst this was an appealing feature initially, I was quickly reminded how specialised all domains of science have become and the enormous background of knowledge required to intelligently converse in each domain. So, I will admit that many of the sessions went over my head. That being said, there was still value in getting a peek into these domains and the types of discussions happening therein.
However, my main reason for attending the conference was one particular thematic track: Software Engineering for Computational Science (SE4Science). In this post, I am going to review this workshop, and I will look at the other sessions of the conference in a future post.
Presentations
The workshop had the following ambitious objectives:
- Provide a venue for members of the SE and research software communities to discuss issues relevant of common interest.
- Identify aspects of SE that should be considered for research software education programs.
- Identify key areas of study where participants agree there is a lack of existing data or studies.
- Support the building of a common research agenda to address the complex software development issues typical of research software.
- Provide a venue for sharing early work and work-in-progress to obtain feedback from the wider community.
The initial session of the workshop consisted of three presentations, all of which are available at this website. Zedong Peng delivered the first presentation on “I/O Associations in Scientific Software: A Study of SWMM (Storm Water Management Model)”, which seeks to address the test oracle problem in scientific software. The test oracle problem, simply put, is the problem of determining the correct output for a given input to your code. This sounds easy, but if you have ever sat down and started to attempt writing automated tests for a piece of research code that has complex and perhaps non-deterministic outputs, then you know how difficult it can be. One approach is to specify behaviours or properties of your system rather than exact specification of the output. Known as “property-based testing”, the presenter dealt with a subclass called metamorphic testing. To generate metamorphic relations used to form tests, one needs to understand the input and output (I/O) relations of the code, and the presenter’s novel approach was to use the user manual and user forums to derive these relationships through statistical methods. It is an interesting approach that mimics what many users do when consulting documentation to figure out the characteristics and behaviours of the program.
The second presentation was titled “Understanding Equity, Diversity and Inclusivity Challenges Within the Research Software Community” and was delivered by Neil Chue Hong. Perhaps unsurprisingly, this was one of the most eye-opening. For me, the stand-out headline was the result from a survey on the diversity of different protected characteristics within the RSE profession (pictured below). In terms of gender and ethnicity, UK RSEs have a significantly smaller representation than either UK Academics or the UK Workforce overall. One can get quite desensitised to the often abysmal diversity statistics reported in the news, so perhaps I shouldn’t have been surprised by these numbers, but I will admit that I hadn’t expected such a large disparity. A partial explanation for this blind spot is my own perception of the RSE community as an incredibly open, friendly, and welcoming one. However, as the presenter responded in the Q&A, there is a difference between a welcoming community and an inclusive one. The analogy was used of a pool party. A welcoming host might tell you to jump on in, but an inclusive one would get out of the pool, lay out the various options to get engaged with the party, and perhaps modify the set up of the party to accommodate your needs. It sounds like quite a high bar, but it is likely part of the solution to rectify the severe disparities in our community.
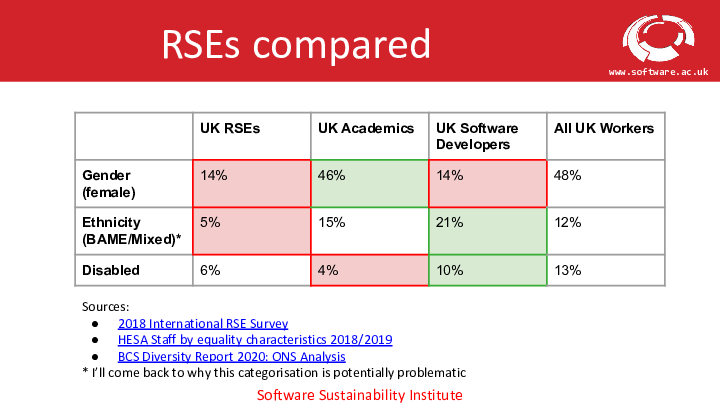 Chue Hong, Neil; Cohen, Jeremy; Jay, Caroline (2021): Understanding Equity, Diversity and Inclusivity Challenges Within the Research Software Community. figshare. Presentation. https://doi.org/10.6084/m9.figshare.14787858.v2.
Chue Hong, Neil; Cohen, Jeremy; Jay, Caroline (2021): Understanding Equity, Diversity and Inclusivity Challenges Within the Research Software Community. figshare. Presentation. https://doi.org/10.6084/m9.figshare.14787858.v2.
I still suspect there are pipeline issues and raised this in the talk. The recruitment pipeline showed the biggest chunk of RSEs coming from a “Physics” background, but this is likely too coarse of a category. Most RSEs are (probably, need data!) coming from subdomains that have a longer history of computation with computers. What is the breakdown of protected characteristics in these areas? We simply don’t have the data on this at the moment. This is not to shift responsibility from the RSE community, but merely to point out that there is probably a concurrent question to answer, which is why there isn’t better representation in computational sciences.
Finally, the third presentation was “How has the COVID-19 Pandemic affected working conditions for Research Software Engineers?” delivered by Caroline Jay. Evidently, this was a pertinent topic given the international pandemic we have all collectively experienced. The basis for the presentation and associated paper was a “diary study” in which participants identifying as RSEs were asked to answer some long form questions about their working situation over the course of a few months immediately after the outbreak of the pandemic. Whilst a comprehensive survey of many RSEs was not possible in this format (sample size was 17), the breadth of responses did seem to capture a representative cross section of how RSEs have weathered the pandemic. Many experiences hit home with me: a porous boundary between work and life, more context switching needed between the two, and a deceptive increase in productivity because of longer hours being worked, leading to a potential for burnout. Overall, the participants reported that the technical side of moving to remote working was not much of a hurdle, which makes sense given the remote nature of much of an RSE’s work and jives with my own experience. Of course, that was not true for everyone, and some did struggle establishing a home office.
On the other hand, I was surprised to see that caring and remote learning duties did not figure as prominently as I would have expected. Parents in the study appeared to have found a good routine. Rather, it was mental health that came to the fore. The loss of casual interactions in workplaces combined with feelings of isolation radically altered the productivity of participants and the ways in which their teams operated. I would summarise the results as such: although RSE work is suited to remote environments, a majority of RSEs still require some level of co-location to operate effectively. Like the authors of this study, I hope that pandemic will bring much needed attention to the diverse needs that RSEs (and all workers) have, and there are some preliminary signs that this is partially underway.