Open and reproducible research with community-driven research software metrics

Open and reproducible research with community-driven research software metrics
 Word cloud generated by
Word cloud generated byCHAOSScon Europe 2020 attendees
By Yo Yehudi, Mateusz Kuzak, and Emmy Tsang
Research software engineers are evaluated like other researchers, largely based on the numbers of publications and citations. However, metrics based on the number of publications encourage re-creating ‘new’ things or re-implementations instead of reuse, and there are huge variations in existing practices to cite software, meaning software isn't always cited or citations aren’t always captured.
We believe that better metrics that reflect the health of research software are crucial to avoid gamification, and that we should be incentivising academic staff who write code and/or research software engineers to follow best software development practices by recognising and rewarding their effort appropriately, and ultimately advancing open science and improving the reproducibility of research.
Tackling the problem
To tackle this problem– we want to learn from how open-source software is evaluated and sustained.
The need to measure the health of software and its ecosystem is not unique to research software – it is also very important for open-source software in general. Different stakeholders within the open-source community, including contributors, community managers, companies, Open-source Project Offices (OSPOs) and funders need to evaluate the impact of their contributions and ensure the quality of their effort, similar to the needs of researchers, research funders and institutions. This led to the creation of the Community Health Analytics Open Source Software (CHAOSS) project, which aims to:
-
Establish standard implementation-agnostic metrics for measuring community activity, contributions, and health
-
Produce integrated open-source software for analysing software community development
Through the work of its various committees and working group, the CHAOSS community explored metrics measuring open-source community health through different lenses, from diversity and inclusion to maturity and risk.
We used the opportunity of two community gatherings prior to FOSDEM to share some of our ideas and interact with and learn from the wider open-source community. These were SustainOSS, a one-day structured discussion on open-source software sustainability, and CHAOSScon, a gathering of the CHAOSS community to discuss metrics for open source communities.
Discussion at Sustain gave extra info and context
The three of us (Emmy, Mateusz, and Yo) joined the SustainOSS Summit. During the morning, we participated in a focus group on how research software differs from other open source software (especially corporate-backed open source software), what new challenges there are, and what needs to be addressed in order to facilitate its sustainability.
We started off with free discussion, sharing our experiences with research software sustainability. The discussion topics that crystallised from this were: (i) challenges in sustaining academic software, (ii) existing initiatives, (ii) efforts on building training to educate academics and research software engineers in good open source practices, and (iv) challenges around open source community building.
One realisation we came to, through this discussion, was that with our disparate backgrounds from around the world, with some participants in academia and others in companies or nonprofits, each of us may mean something different when we talk about software sustainability. Given limited time, we parked that discussion for later. Unfortunately, we did not have enough time to come back to it, which is really a pity.
After the brainstorming session, the group discussed each of the points above, and managed to compile a list of challenges, initiatives and training resources we were familiar with (or running ourselves). Outcomes from the session (and the rest of the event) are currently being compiled - look out for the SustainOSS resource list, coming soon!
Some of the main challenges we agreed on were: lack of reward system, lack of awareness from the funders' side and unprepared, uninterested or untrained academics.
We agreed that the most interesting follow up from this session would be a compilation of examples of the exemplar projects that address software sustainability from the start, and some templates on how to pitch the importance of software sustainability to the funders to raise their awareness.
A chaotic (but fabulous) session at CHAOSScon
At CHAOSSCon the next day, we ran a 20-minute session on metrics in research software.
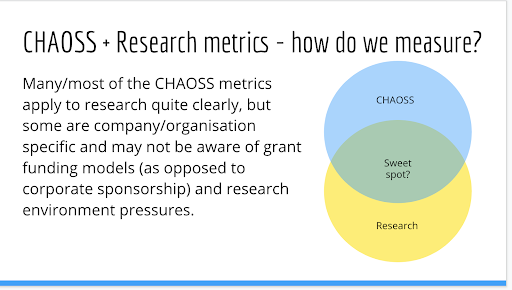
This is a scenario where we had more identified problems, perhaps, than we had solutions. There are some great starting points - the CHAOSS metrics are designed to measure open source software projects and communities, but it didn’t seem to be a 100% overlap with the needs of research software. Research has different prestige and credit structures to those of most companies (papers, journal prestige, citations, for example), and is often bound up in fixed-term grant periods of a few years. Many instances of research software are very niche and may not be used by anyone outside the specific research domain. Companies, meanwhile, may be contributing to software used broadly across computing (the Linux kernel being a good example of this), and have a vested interest in keeping their software stacks stable and maintainable in the long term.
Rather than spending a full talk explaining this, we decided to shorten the talk and spend a few minutes in a break-out session, asking folks to brainstorm what metrics might be useful for research, given the differences we explained above. With only 20 minutes for the whole session, it was a bit tight, but we managed to break it up: eight minutes talking, eight minutes of group break-out discussion, and four minutes group discussion / wrap up. Thankfully, this actually worked, and fit into the time slot without overrunning.
Results from CHAOSScon
Given how short the CHAOSScon session was, we decided to forgo the trusted post-it notes and instead ask people to upload their ideas directly onto sli.do. This produced a word cloud, and we exported the full set of responses onto GitHub to allow free and easy access and analysis.
It is perhaps unsurprising that many of the metrics proposed were actively used in open-source software communities, including collaboration metrics like number of contributors, commits, and pull requests. While these may be considered “obvious” in measuring open-source community health, collaboration is at the moment nowhere as highly valued in the research software communities, and not as crucial to the viability of the research software project. Having tools and visualisations to help keep track of these metrics would give the opportunity to change things for the better.
Another group of interesting ideas relate to diversity and health of contributors. These include sentiments of and number of commits per contributor, as well as the affiliations of contributors and maintainer. This again reflects aspects of research culture that are currently undervalued and could potentially benefit from easier ways of capture and measurement. It also prompted a discussion on facilitating and highlighting contributions from traditionally under-represented research communities.
Other themes that emerged included code reusability and robustness, especially in relation to downstream dependencies. Active development and maintenance was also proposed. These are very desirable characteristics of research software as they reflect the usefulness of the software. Currently, downstream dependencies are usually only tracked via software citation, so it would be useful to have tools or methods to capture software dependencies, and not just the papers that depend on the software. Given that software sustainability and maintenance are increasingly discussed and valued within research communities, having metrics that could capture downstream dependencies would be immensely helpful for institutions as well as research funders to identify people and areas of work to support.
Slides are available on Google Drive or the CHAOSS site. Emmy also live-tweeted the session!
Visions and future efforts
SustainOSS, CHAOSScon, and FOSDEM gave us an opportunity to break down many of the problems, and identify more questions we wanted to answer. For example, if we’re measuring research software projects with an aim to see how sustainable they are, how do we define sustainability? Additionally, there are many other best practice efforts for research software, such as various FAIR initiatives, best practice working groups, and hack events. Should these be looped in to the metrics effort, and if so, how?
We also saw the importance of cross-community discussion - as researchers at an open-source-software oriented event, we had the chance to meet others in similar domains and see some of the differences and similarities between our interests and struggles. This raises the question - are there other communities that might have useful suggestions - perhaps closed-source proprietary developers, or maybe some other related area?
Within the research domain, we would like to create a set of metrics for open source / research software - if you’re a researcher, group, or initiative investigating this, and would like to collaborate, please contact us or link in to CHAOSS efforts.