
Automating unit testing with Continuous Integration
 Photo by Sam Moghadam Khamseh
Photo by Sam Moghadam KhamsehBy Steve Crouch, SSI Research Software Group lead.
This guide is the first in the Unit Testing for Scale and Profit series.
In a project where changes are frequently made to research software, it is helpful to know that the code still works as expected. In our last two episodes, we looked at the benefits of having a set of unit tests and how we can use test parameterisation to write numerous tests efficiently. However, particularly with projects involving more than one contributor, it would be good to have assurance the software still works without everyone having to pull down all the changes and test them. In this guide, we'll be looking at Continuous Integration, which aims to reduce this burden by automating things in the background, such as running tests. But it also can be used for so much more.
Writing and using unit tests is a great way to check that your software runs and generates results as it should. If we also take into account any testing required on different target user platforms for our software (potentially with changes being made to many repository branches at the same time), the effort required to conduct testing at this scale can quickly become intractable for a research project to sustain.
Automation - wherever possible - helps us to reduce errors and makes predictable processes more efficient. The idea is that when a new change is committed to a repository, Continuous Integration (or CI for short) clones the repository containing code, builds it if necessary, and runs any tests for you automatically. Once complete, it presents a report to let you see what happened, and this potentially saves us a lot of time since it all happens in the background. As we'll see in this episode, it also gives us the opportunity to scale up our testing even further, by running tests across many operating systems and Python versions simultaneously.
There are many CI infrastructures and services, free and paid for, and subject to change as they evolve their features. We’ll be looking at GitHub Actions - which unsurprisingly is available as part of GitHub.
In the previous episodes, we looked at a Python implementation of the Factorial function, wrote some unit tests for it, and used parameterisation to allow us to scale up the writing of our tests more efficiently. If you've already followed these episodes, feel free to continue. Otherwise, if you would like some background on writing basic unit tests, feel free to go back and follow them to bring you up to speed.
Note: you will need Python 3.7 or above, and some basic experience with using Git and an account on GitHub, to follow this guide.
A quick catch-up from last time...
We'll be reusing the code used in the previous two episodes in this series, and for convenience, this code has been put into a repository on GitHub. We'll be making changes to this repository throughout this guide, so you'll need to first make your own copy of it by following the repository link and selecting Use this template and giving it the repository name ci-guide-example. You can specify this repository as either public or private.
Once you have your own GitHub copy of this repository, then you can clone it and set up its virtual environment using (replacing username with your own GitHub username):
$ git clone https://github.com/username/ci-guide-example.git $ cd ci-guide-example $ python3 -m venv venv $ source venv/bin/activate $ python3 -m pip install -r requirements.txtYou can take a look at the Factorial code in mymath/factorial.py, and run the code in the Python interpreter yourself, for example:
>>> from mymath.factorial import factorial >>> factorial(3) 6You can find the parameterised unit tests in tests/test_factorial.py, which can be run using:
$ python3 -m pytest --cov=mymath.factorial tests/test_factorial.pyWhich should yield 4 successfully run unit tests, shown by 'tests/test_factorial.py ....'.
So what's YAML, and why do I need it?
YAML is a text format used by GitHub Action workflow files. It is also increasingly used for configuration files and storing other types of data, so it’s worth taking a bit of time looking into this file format.
YAML (a recursive acronym which stands for “YAML Ain’t Markup Language”) is a language designed to be human-readable. The three basic things you need to know about YAML to get started with GitHub Actions are key-value pairs, arrays, and maps.
So firstly, YAML files are essentially made up of key-value pairs, in the form key: value, for example:
name: Kilimanjaro height_metres: 5892 first_scaled_by: Hans MeyerIn general, you don’t need quotes for strings, but you can use them when you want to explicitly distinguish between numbers and strings, e.g. height_metres: "5892" would be a string, but in the above example it is an integer. It turns out Hans Meyer isn’t the only first ascender of Kilimanjaro, so one way to add this person as another value to this key is by using YAML arrays, like this:
first_scaled_by: - Hans Meyer - Ludwig PurtschellerIf we wanted to express more information for one of these values we could use a feature known as maps, which allow us to define nested information, for example:
... height: value: 5892 unit: metres measured: year: 2008 by: Kilimanjaro 2008 Precise Height Measurement Expedition ...So here, height itself is made up of three keys value, unit, and measured, with the last of these being another nested key with the keys year and by. Note the convention of using two spaces for tabs, instead of Python’s four.
We can also combine maps and arrays to describe more complex data. Let’s say we want to add more detail to our list of initial ascenders:
... first_scaled_by: - name: Hans Meyer date_of_birth: 22-03-1858 nationality: German - name: Ludwig Purtscheller date_of_birth: 22-03-1858 nationality: AustrianSo here we have a YAML array of our two mountaineers, each with additional keys offering more information. As we’ll see shortly, GitHub Actions workflows will use all of these.
Defining a CI workflow
With a GitHub repository, there’s a way we can set up CI to run our tests automatically when we commit changes. First, create the new directories .github and .github/workflows:
$ mkdir -p .github/workflowsNB: in Windows, you can create these directories using File Explorer.
This directory is used specifically for GitHub Actions, allowing us to specify any number of workflows that can be run under a variety of conditions, which is also written using YAML. So let’s add a new YAML file called main.yml (note its extension is .yml without the a) within the new .github/workflows directory:
# We can name this workflow whatever we like name: CI # We can specify which Github events will trigger a CI build on: push # now define a single job 'build' (but could define more) jobs: build: # we can also specify the OS to run tests on runs-on: ubuntu-latest # a job is a seq of steps steps: # Next we need to checkout repository and set up Python # A 'name' is just an optional label shown in the log - helpful to clarify progress - and can be anything - name: Checkout repository uses: actions/checkout@v2 - name: Set up Python 3.9 uses: actions/setup-python@v2 with: python-version: 3.9 - name: Install Python dependencies run: | python3 -m pip install --upgrade pip python3 -m pip install -r requirements.txt - name: Test with pytest run: | python3 -m pytest --cov=mymath.factorial tests/test_factorial.pyNB: be sure to create this file as main.yml within the newly created .github/workflows directory, or it won’t work!
So as well as giving our workflow a name - CI - we indicate with on that we want this workflow to run when we push commits to our repository. The workflow itself is made of a single job named build, and we could define any number of jobs after this one if we wanted, and each one would run in parallel.
Next, we define what our build job will do. With runs-on we first state which operating systems we want to use, in this case just Ubuntu for now. We’ll be looking at ways we can scale this up to testing on more systems later.
Lastly, we define the steps that our job will undertake in turn, to set up the job’s environment and run our tests. You can think of the job’s environment initially as a blank slate: much like a freshly installed machine (albeit virtual) with very little installed on it, we need to prepare it with what it needs to be able to run our tests. Each of these steps are:
- Checkout repository for the job: uses indicates that want to use a GitHub Action called checkout that does this
- Set up Python 3.9: here we use the setup-python Action, indicating that we want Python version 3.9
- Install the latest version of pip and our dependencies: it’s good practice to upgrade the version of pip that is present first, then we use pip to install our package dependencies just as we could do on our own machine. We use run here to run these commands in the CI shell environment
- Test with pytest: lastly, we run pytest, with the same arguments we used manually before
Trigger a run of our tests on GitHub
Now if we commit and push this change a CI run will be triggered:
$ git add .github $ git commit -m "Add GitHub Actions configuration" $ git pushThis will happen every time we commit any set of changes to our repository, including those commits made by others.
Checking build progress and reports
Handily, we can see the progress of the build from our repository on GitHub by selecting commits, located just above the code directory listing on the right, alongside the last commit message and a small image of a timer.
 Screenshot showing the last repository commit triggering a GitHub Actions job being run
Screenshot showing the last repository commit triggering a GitHub Actions job being run
You’ll see a list of commits and likely see an orange marker next to the latest commit (clicking on it yields Some checks haven’t completed yet) meaning the build is still in progress. This is a useful view, as over time it will give you a history of commits, who did them, and whether the commit resulted in a successful build or not.
Hopefully, after a while, the marker will turn into a green tick indicating a successful build. Clicking it gives you even more information about the build and selecting the Details link takes you to a complete log of the build and its output.
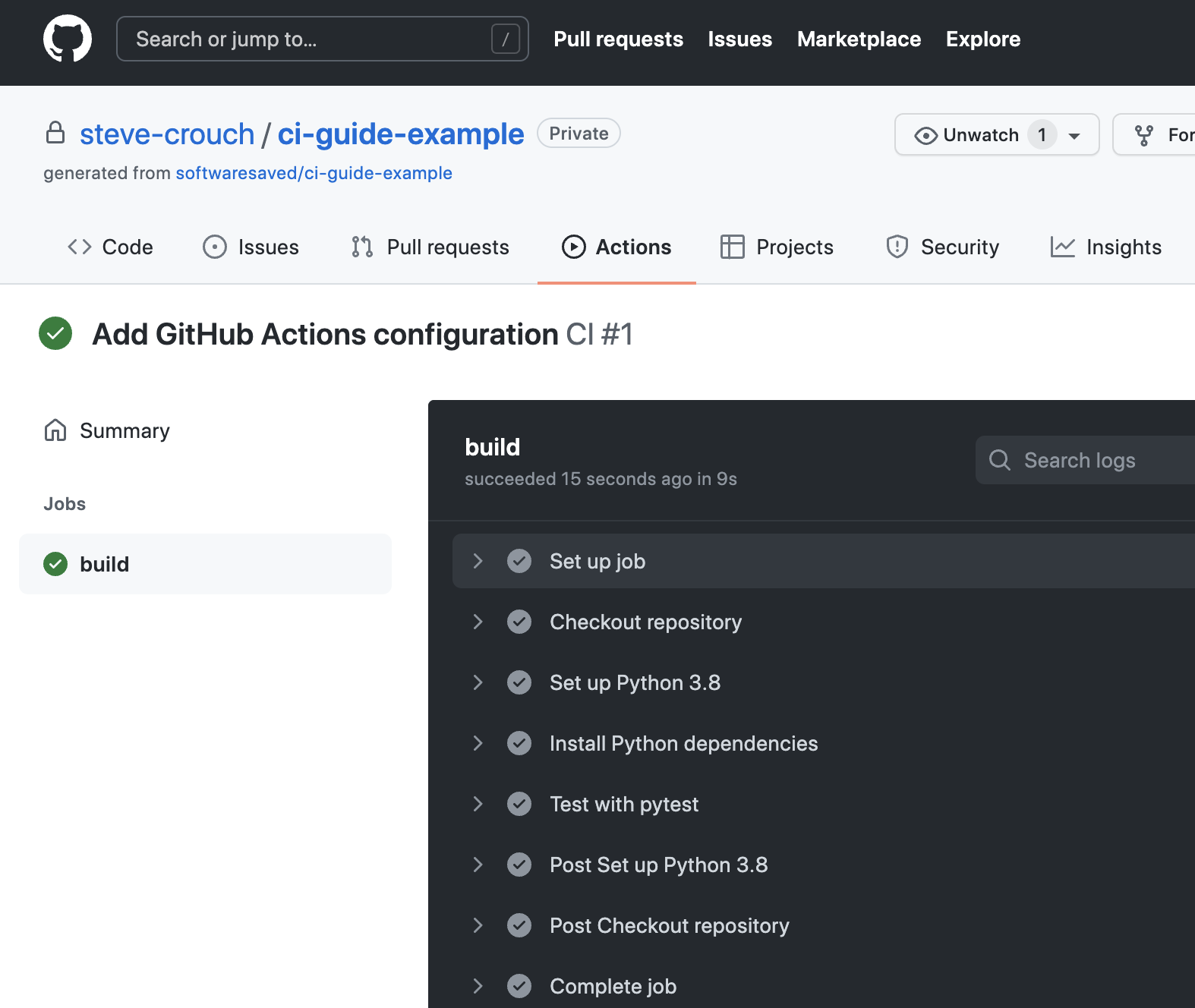 Screenshot showing each task of GitHub Actions job being successfully completed
Screenshot showing each task of GitHub Actions job being successfully completed
The logs are actually truncated; selecting the arrows next to the entries - which are the name labels we specified in the main.yml file - will expand them with more detail, including the output from the actions performed.
Scaling Up Testing Using Build Matrices
Now we have our CI configured and building, we can use a feature called build matrices which really shows the value of using CI to test at scale.
Suppose the intended users of our software use either Ubuntu, Mac OS, or Windows, and either have Python version 3.8 or 3.9 installed, and we want to support all of these. Assuming we have a suitable test suite, it would take a considerable amount of time to set up testing platforms to run our tests across all these platform combinations. Fortunately, CI can do the hard work for us very easily.
Using a build matrix we can specify testing environments and parameters (such as operating system, Python version, etc.) and new jobs will be created that run our tests for each permutation of these.
Let’s see how this is done using GitHub Actions. To support this, change your .github/workflows/main.yml to the following:
... runs-on: ${{ matrix.os }} strategy: matrix: os: [ubuntu-latest, macos-latest, windows-latest] python-version: [3.8, 3.9] # a job is a seq of steps steps: # Next we need to checkout repository and set up Python # A 'name' is just an optional label shown in the log - helpful to clarify progress - and can be anything - name: Checkout repository uses: actions/checkout@v2 - name: Set up Python uses: actions/setup-python@v2 with: python-version: ${{ matrix.python-version }} ...Here, we are specifying a build strategy as a matrix of operating systems and Python versions, and using matrix.os and matrix.python-version to reference these configuration possibilities instead of using hardcoded values. The ${{ }} are used as a means to reference these configuration values. So every possible permutation of Python versions 3.8 and 3.9 with the Ubuntu, Mac OS and Windows operating systems will be tested, so we can expect 6 build jobs in total.
Let’s commit and push this change and see what happens:
$ git add .github/workflows/main.yml $ git commit -m "Add GA build matrix for os and Python version" $ git pushIf we go to our GitHub build now, we can see that a new job has been created for each permutation (the Python versions referenced will differ from the 3.8 and 3.9 depicted):
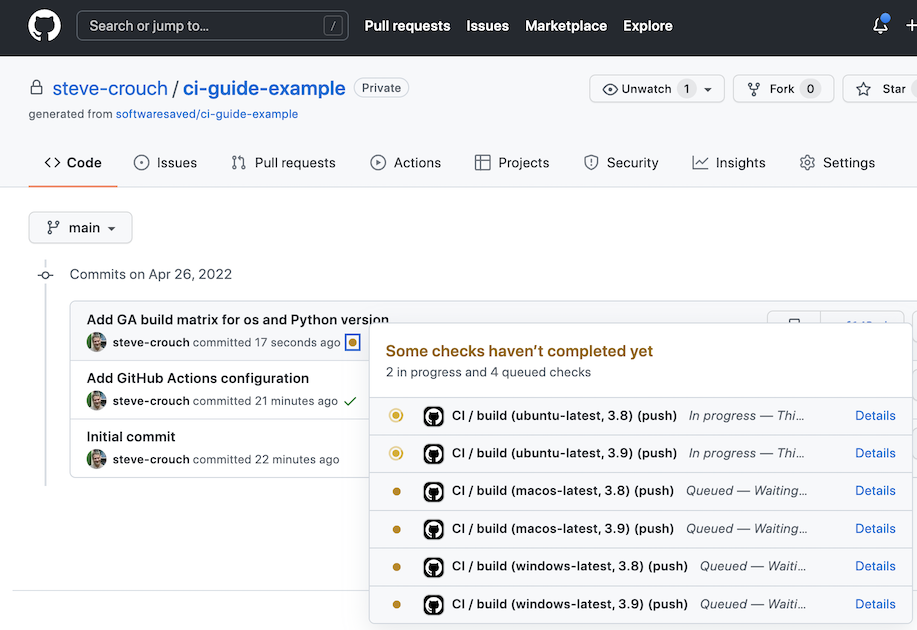 Screenshot showing progress running multiple jobs specified using a build matrix
Screenshot showing progress running multiple jobs specified using a build matrix
Note that all jobs running in parallel (up to the limit allowed by our account) which potentially saves us a lot of time waiting for testing results. Overall, this approach allows us to massively scale our automated testing across platforms we wish to test.
What about doing other things with CI?
We've focused on using CI to demonstrate running sets of unit tests, using standard GitHub Actions (indicated by actions/ when we specify one of them). But we're not constrained to doing only this.
Beyond the standard set of actions, others are available via the GitHub Marketplace. It contains many third-party actions (as well as apps) that you can use with GitHub for many tasks across many programming languages, particularly for setting up environments for running tests, code analysis and other tools, setting up and using infrastructure (for things like Docker or Amazon’s AWS cloud), or even managing repository issues. You can even develop and contribute your own GitHub Actions to the Marketplace.
What's next?
Our previous episodes looked at writing and running unit tests to check our code's correctness, with parameterisation allowing us to more easily reuse testing code and helping us scale up how many tests we can write. This episode, which concludes the Unit Testing for Scale and Profit series, has explored scaling up even further. After writing a workflow, it allows us to make use of free infrastructure to check our code's correctness automatically in the background as changes are made to our codebase. And beyond that, checking its correctness across different platforms and language versions, at no extra cost.
The scale of testing is taken even further if you make use of Git branches in your development. By default, since Github Action workflows operate on the branches to which they are committed, having a workflow present in all the various repository branches gives you an idea of the code correctness of that branch. Additionally, and more specifically, if using feature-branch workflow it can indicate the state of a branch following a merge from another branch. For example, after development on a branch dedicated to implementing a specific feature is complete and merged into a higher-level branch, the workflow will essentially check that the new feature doesn't break anything else on that branch, which may contain many other new merged features.
As we've mentioned, automation wherever possible is a good thing. It saves us time and captures complex processes that allow ourselves and others to more easily reproduce our work.