Introducing pydbgen: A random dataframe/database table generator
Introducing pydbgen: A random dataframe/database table generator
 Image by Tirthajyoti Sarkar.
Image by Tirthajyoti Sarkar.By Tirthajyoti Sarkar, ON Semiconductor.
This post was first published in Towards Data Science blog.
Often, beginners in SQL or data science struggle with the matter of easy access to a large sample database file (.DB or .sqlite) for practicing SQL commands. Would it not be great to have a simple tool or library to generate a large database with multiple tables, filled with data of one’s own choice?
When you start learning and practicing data science, often the biggest worry is not the algorithms or techniques but availability of raw data. Fortunately, there are many high-quality real-life datasets available on the web for trying out cool machine learning techniques. However, from my personal experience, I found that the same is not true when it comes to learning SQL. Now, for data science - having a basic familiarity of SQL is almost as important as knowing how to write code in Python or R. But access to a large enough database with real data (such as name, age, credit card, SSN, address, birthday, etc.) is not nearly as common as access to toy datasets on Kaggle, specifically designed or curated for machine learning task.
Apart from the beginners in data science, even seasoned software testers may find it useful to have a simple tool where with a few lines of code they can generate arbitrarily large data sets with random (fake) yet meaningful entries.
I am glad to introduce a lightweight Python library called pydbgen. You can read in details about the package here. I am going to go over similar details in the short article.
What exactly is pydbgen?
It is a lightweight, pure-python library to generate random useful entries (e.g. name, address, credit card number, date, time, company name, job title, license plate number, etc.) and save them in either Pandas dataframe object, or as a SQLite table in a database file, or in a MS Excel file.
How to install it?
It’s (current version 1.0.5) hosted on PyPI (Python Package Index repository). Remember you need to have Faker installed to make this work. So, just type,
pip install pydbgenNote, it’s currently only tested on Python 3.6. It won’t work on Python 2 installations.
How to use it?
You have to initiate a pydb object to start using it.
import pydbgen from pydbgen import pydbgen myDB=pydbgen.pydb()After that, you can access the various internal functions exposed by the pydbobject. For example to print random US cities,
myDB.city_real() 'Otterville' for _ in range(10): print(myDB.license_plate()) 8NVX937 6YZH485 XBY-564 SCG-2185 XMR-158 6OZZ231 CJN-850 SBL-4272 TPY-658 SZL-0934If you just say 'city' instead of 'city_real', you will get fictitious city names :)
print(myDB.gen_data_series(num=8,data_type='city')) New Michelle Robinborough Leebury Kaylatown Hamiltonfort Lake Christopher Hannahstad West AdamboroughHow to generate a Pandas dataframe with random entries?
You can choose how many and what data types to be generated. Note, everything is returned as string/texts.
testdf=myDB.gen_dataframe(5,['name','city','phone','date'])The resulting dataframe looks like following,
|
names |
city |
phone-number |
date |
|
|
0 |
James Bass |
Fife Lake |
340-848-7354 |
2010-12-11 |
|
1 |
Cody Werner |
Topanga |
326-520-2048 |
1996-12-22 |
|
2 |
Joshua West |
Richwoods |
265-159-8349 |
2012-03-12 |
|
3 |
Kenneth Hanson |
Northfields Woods |
184-496-6411 |
1979-07-12 |
|
4 |
Michelle Brown |
Lake Beulah |
554-703-6417 |
1986-06-04 |
How to generate a Database Table?
You can choose how many and what data types to be generated. Note, everything is returned as text/VARCHAR data type for the database. You can specify the database file name and the Table name.
myDB.gen_table( db_file='Testdb.DB', table_name='People', fields=['name','city','street_address','email'] )This generates a .DB file which can be used with MySQL or SQLite database server. The resulting database table was opened in DB Browser for SQLite and looks like following,
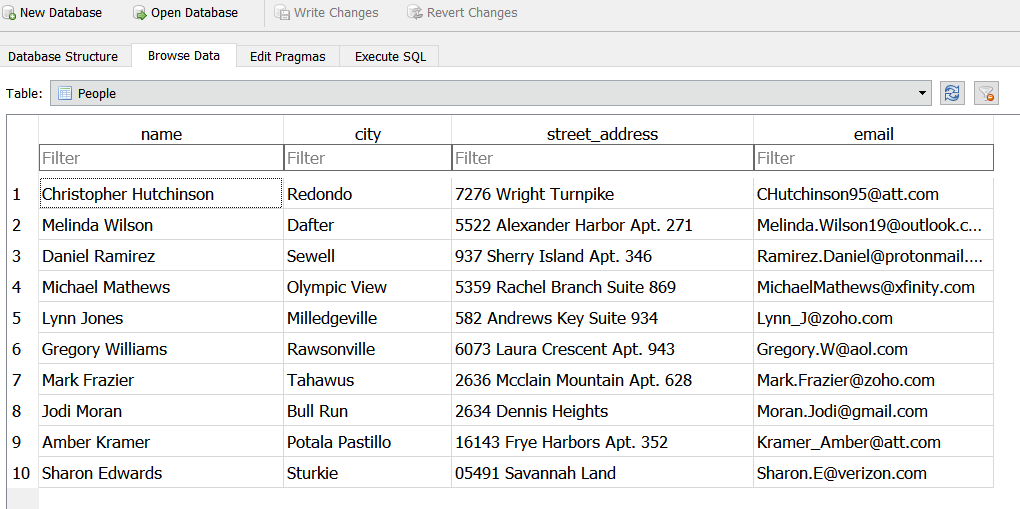 Image by Tirthajyoti Sarkar.
Image by Tirthajyoti Sarkar.How to generate an Excel file?
Similar to above, just use the following code to generate an Excel file with random data. Note the 'simple_phone' set is set to False, thereby generating complex long-form phone numbers. This can come handy to experiment with more involved data extraction codes!
myDB.gen_excel( num=20, fields=['name','phone','time','country'], phone_simple=False, filename='TestExcel.xlsx' )The resulting file looks like…
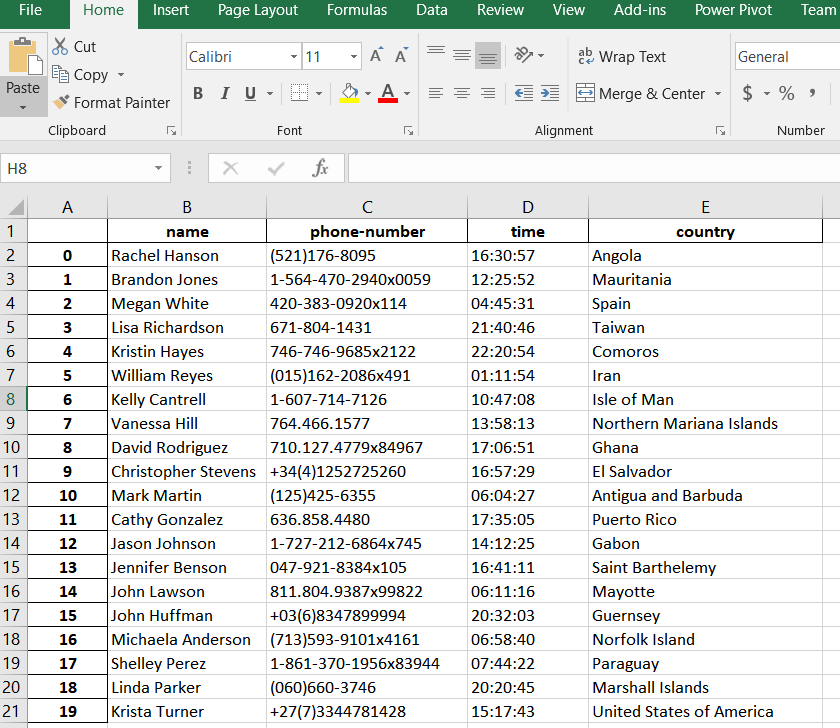 Image by Tirthajyoti Sarkar.
Image by Tirthajyoti Sarkar.A cool way to generate random email IDs for scrap use?
One built-in method in pydbgen is realistic_email , which generates random email IDs from a seed name. Can you think of any use of this on the web where you don’t want to give out your real email ID but something close?
myDB.gen_excel( num=20, fields=['name','phone','time','country'], phone_simple=False, filename='TestExcel.xlsx' ) Tirtha_Sarkar@gmail.com Sarkar.Tirtha@outlook.com Tirtha_S48@verizon.com Tirtha_Sarkar62@yahoo.com Tirtha.S46@yandex.com Tirtha.S@att.com Sarkar.Tirtha60@gmail.com TirthaSarkar@zoho.com Sarkar.Tirtha@protonmail.com Tirtha.S@comcast.netFuture Improvements and user contributions
The current version is 1.0.5 and may contain many bugs. If you notice any and your program crashes during execution (except for bad entry by you), please let me know. Also, if you have cool idea to contribute to the source code, the Github repo is all open for you. Some questions readily come to mind,
-
Can we integrate some machine learning/statistical modeling with this random data generator?
-
Should visualization function be added to the generator?
Possibilities are endless and exciting…