Improved code for ARCHER hits the target
Improved code for ARCHER hits the target
 By Gillian Law, TechLiterate, talking with Prashant Valluri, University of Edinburgh.
By Gillian Law, TechLiterate, talking with Prashant Valluri, University of Edinburgh.
This article is part of our series: Breaking Software Barriers, in which Gillian Law investigates how our Research Software Group has helped projects improve their research software. If you would like help with your software, let us know.
There's a difference between writing code and writing good code, says Prashant Valluri, Lecturer at the University of Edinburgh's Institute for Materials and Processes, laughing as he describes how much he learned while working with the Software Sustainability Institute.
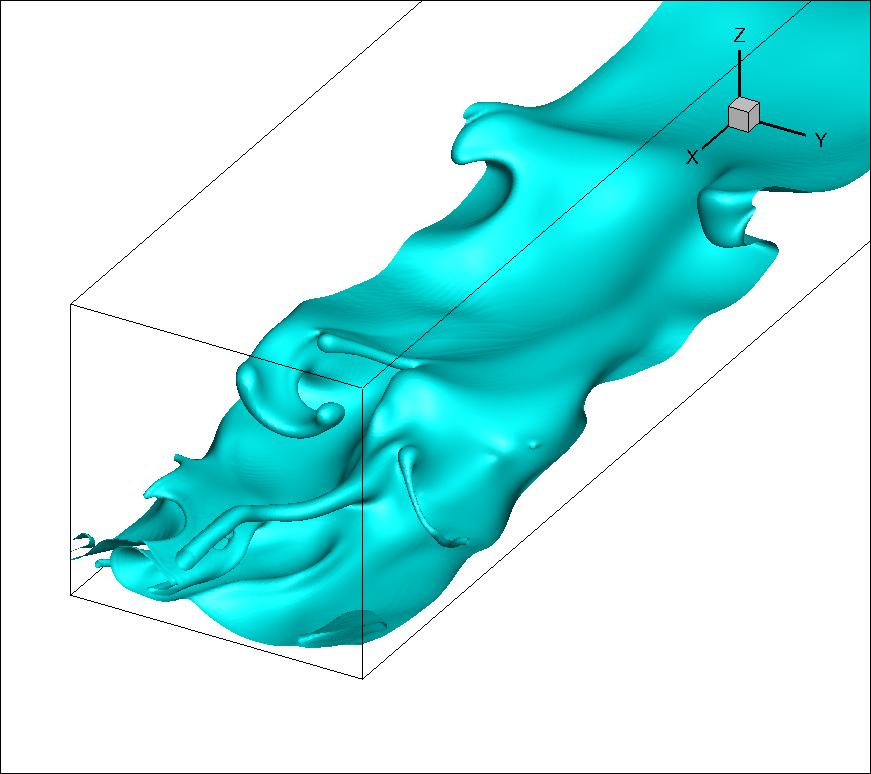
Valluri's team has developed code called TPLS (Two-Phase Level Set), for mathematically modelling complex fluid flows. The code aims to provide much more effective computational fluid dynamics (CFD) analysis for academia and industry, by providing efficient multi-phase models, better numerical resolution and efficient parallelisation.
TPLS uses an ultra-high resolution 3D Direct Numerical Simulation approach combined with the Level-Set method for tracking the developing interface between phases. It employs a 2D Message Passing Interface (MPI) process decomposition coupled with a hybrid OpenMP parallelisation scheme to allow scaling to thousands of CPU cores.
After an open source version of the software was launched on SourceForge in May 2013, the team contacted the Software Sustainability Institute to ask for help in making the code accessible to a wider range of developers.
"It was hardcore code, and people with serious Fortran experience could work with it, but in order to broaden the audience it needed work," says Valluri.
Then there was the issue of his idiosyncratic coding. "I write my own code – but it's horrible, in the way my logic works! It was really interesting to watch how the professionals make sure it's optimised and user friendly – and a good learning experience for me."
Working with the Institute's Research Software Group
From the start, Valluri says working with the Institute team was brilliant.
"We had regular meetings, both with the Software Sustainability Institute and with the ARCHER eCSE team [Embedded Computational Science & Engineering, which provides support to help users run on the ARCHER supercomputer], so the code was improved as we went.
"You can do development on your own for so long, and things seem to be running without any bugs, but when you try to move to a supercomputer, like ARCHER, then the skeletons fall out of cupboards!"
Timing was tight, so the team had to choose what could be done, Valluri explains.
"We had several things planned, but we decided to focus on the most important bits: bugs, versions, and some design improvements. Mike Jackson helped us to redesign the code with more flexible logic, and input files that could be read in a simple manner. He developed a Quick Start guide for new users, and a configuration scheme that allows TPLS to be set up by editing input files, not code. The usability is vastly improved."
The configuration files store information that affects the simulation of velocity, pressure, flow, thickness of fluids and other phenomena. By using these files, researchers don't need to edit program code or even understand it in order to use it in their work.
TPLS has also been split into two programs, one to create the data and one to run the simulation. The data can be created on a desktop or laptop computer, reducing the amount of time needed on a cluster or supercomputer.
Documentation on the architecture of the code, coding standards and an example model suite have had to be postponed, but Valluri states that the team will get back to these as soon as possible. For now, he has code that can be worked on by any developer who is interested in helping.
Doing things right is worth the effort
"I have learned so much through this," Valluri says. "I didn't know how to make code user-friendly – there's a lot more to usability than how it looks. It's not about the GUI (graphical user interface) - that comes much later. It's more about making sure the audience knows what the software does. If we just make it 'our way' then we can use it, but it’s impossible for non-experts to understand.
"It adds development time, doing things right, but it's worth it. Our code is miles away from where it was.
"It's really made a profound change to the way we do coding, even down to the way I write lines of code. We now understand the complexity involved in making things run smoothly – it's really been a very good learning experience."
A new version of the code will be made available as open source in February 2015 and Valluri hopes to see many new users and developers getting involved. Industrial partners, too, including Shell, are keen to use the new code once it is available.
"There's lots more to be done in subsequent collaborations. I am building the use of SSI into everything I do in future!" he concludes.
If you'd like free help to assess or improve your software, why not submit an application into the Institute's Open Call?